When to Implement AI: A Technical PM’s Guide to the AI Stack
We’ve all at some point been wowed by the capabilities of LLMs. We’ve also been frustrated by their often nonsensical responses. Nonetheless, investors and executive teams want strategies for AI. At the same time, engineers are dreading the messy reality of implementation.
As Product Managers, it’s our job to cut through the noise. But the hard truth is that “AI” is takes many forms, and most of them are not chatbots.
For the decade prior to ChatGPT, we weren’t building interfaces to rewrite emails. We were building systems that made decisions. In this era, the technical problem wasn’t “generate a creative image.” or “summarize this article.” The problem was “Here is an image; is it a cat or a dog?” or “Here is a transaction; is it legitimate?”
Before we tried to fit the Square Peg of Generative AI into every hole, we had Round Peg solutions for “Round Hole” problems. These were the architectures that built the modern internet. To build a real strategy, you need to know what they are, because often, they are still the better tool.
The Specialists
Beyond traditional logic and databases, three types of model-based decision-making dominated the industry before 2023. These systems were largely discriminative. They didn’t create new data; they classified and transformed existing data.
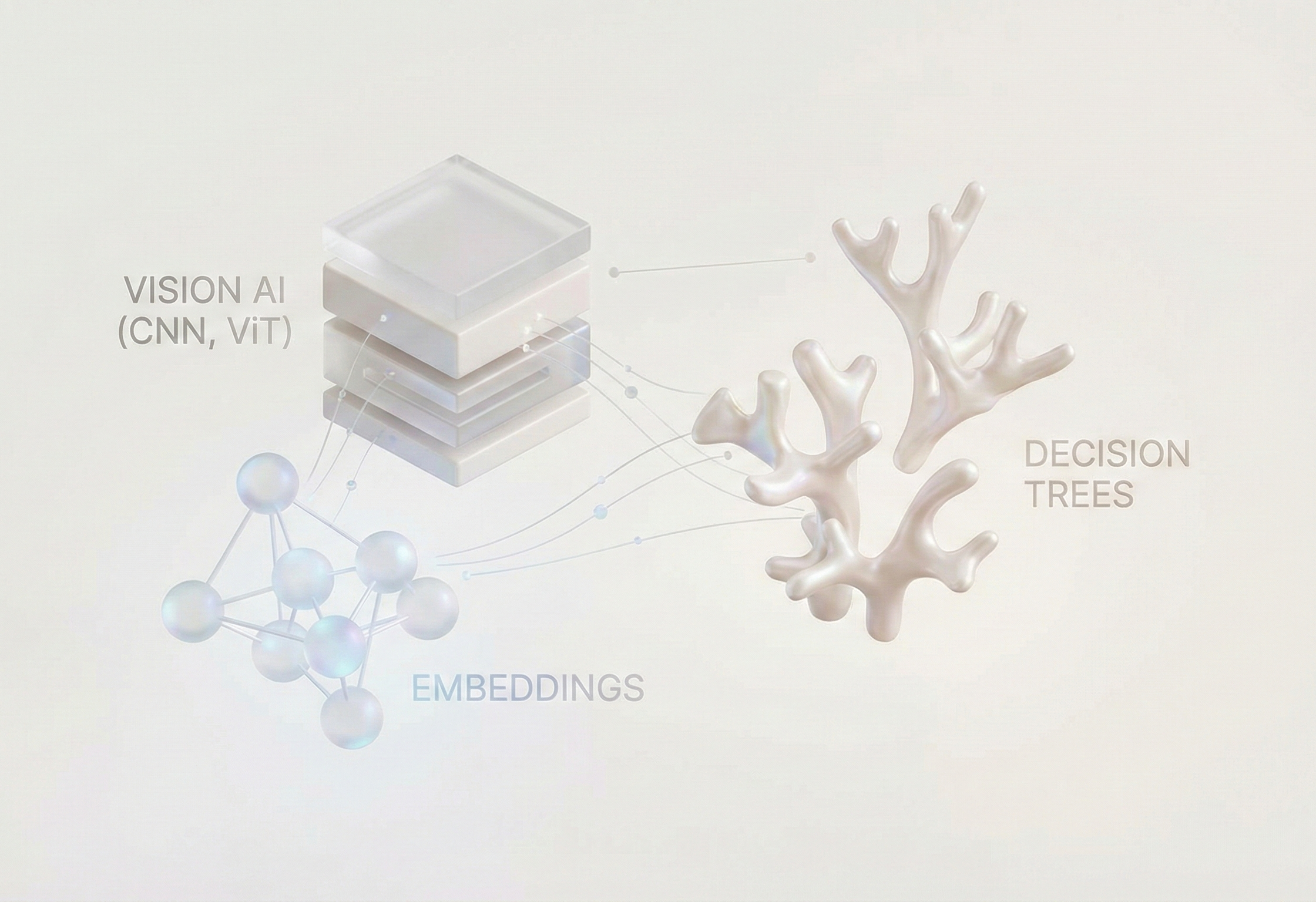
Convolutional Neural Networks (CNNs): After AlexNet won the ImageNet competition in 2012, CNNs became the kings of deep learning. Models like ResNet and YOLO (You Only Look Once) could classify images with superhuman accuracy. These models became the foundation for Content moderation, medical imaging, autonomous driving, and more.
Recommendation Systems: While Vision got the headlines, Recommender Systems got the budget. These alogrithms still power content and product recommendations on platforms like TikTok, Netflix, and Amazon. It was a game-changer because it solved the problem of “how do you predict if User A will like Item B?” the answer was Embeddings. We learned to treat users and items or content as vectors in a shared space and if the vectors lined up, we recommended it. This was the industrialization of “semantic search” long before we applied it to chatbots, and is the foundation for many RAG implementations today.
Gradient Boosted Trees (XGBoost): If you walk into a bank or an insurance company today, they aren’t using an LLM to decide your mortgage rate. They are using XGBoost. This is because organizations are working with structured, messy tabular data (income, zip code, credit score). These models are perfect for this use case because they’re interpretable, fast, and mathematically rigorous. They don’t need to Reason out the answer, they just need to match patterns.
The “Bitter Lesson”
So why did everything change? Why are we now obsessed with Generative models?
The answer lies in Rich Sutton’s essay, “The Bitter Lesson.” It argues that in the long run, leveraging massive computation (search and learning) always beats human-designed complexity.
In the “Round Peg” era, we had to hand-craft features. If you wanted to predict house prices, you had to write code to extract “number of windows” or “roof type.” We spent years building these pipelines, only to find that if you just feed enough data into a massive neural network (like a Transformer), it learns better features than we can code.
Models like AlphaGo (Reinforcement Learning) and AlphaFold (Transformers) proved that if you have enough scale, computers can find solutions that seem illogical to human experts but are mathematically superior.
This brings us to the Square Peg problem. We now have models (LLMs) that are incredibly powerful generalists. They can code, write, summarize, and reason. But they come with a Probabilistic Tax: they are expensive, slow, and sometimes they lie.
When to use the Square Peg?
As a PM, instead of asking “Where can I implement AI?”, ask:
“Is my problem a Creation problem or a Decision problem?”
“Is the the data I’m working with structured or noisy?”
“How fast does it need to be?”
“How precise does it need to be?”
The Future is Hybrid The most sophisticated products today don’t choose one or the other. They use Hybrid Architectures.
Consider a modern Search feature: The Round Peg (Embeddings): The user asks for date night ideas. The system uses vector search (RecSys tech) to find 50 relevant restaurants. It is fast and structured.
The Square Peg (LLM): The system passes the 50 restaurants to an LLM to summarize them: “Here are 3 romantic spots near you with availability tonight.”
The Takeaway:Don’t let the hype cycle dictate your features. If you need to find the truth, use Search/Embeddings. If you need to predict a risk, use XGBoost. If you need to synthesize or create something new from that data, pay the tax and use an LLM.
Good AI product management isn’t about using the latest model. It’s about knowing when not to use it.