AI-Powered Career Matching Platform
CareerMatchr allowed me to move from searching for Jobs to being one of the first to apply.
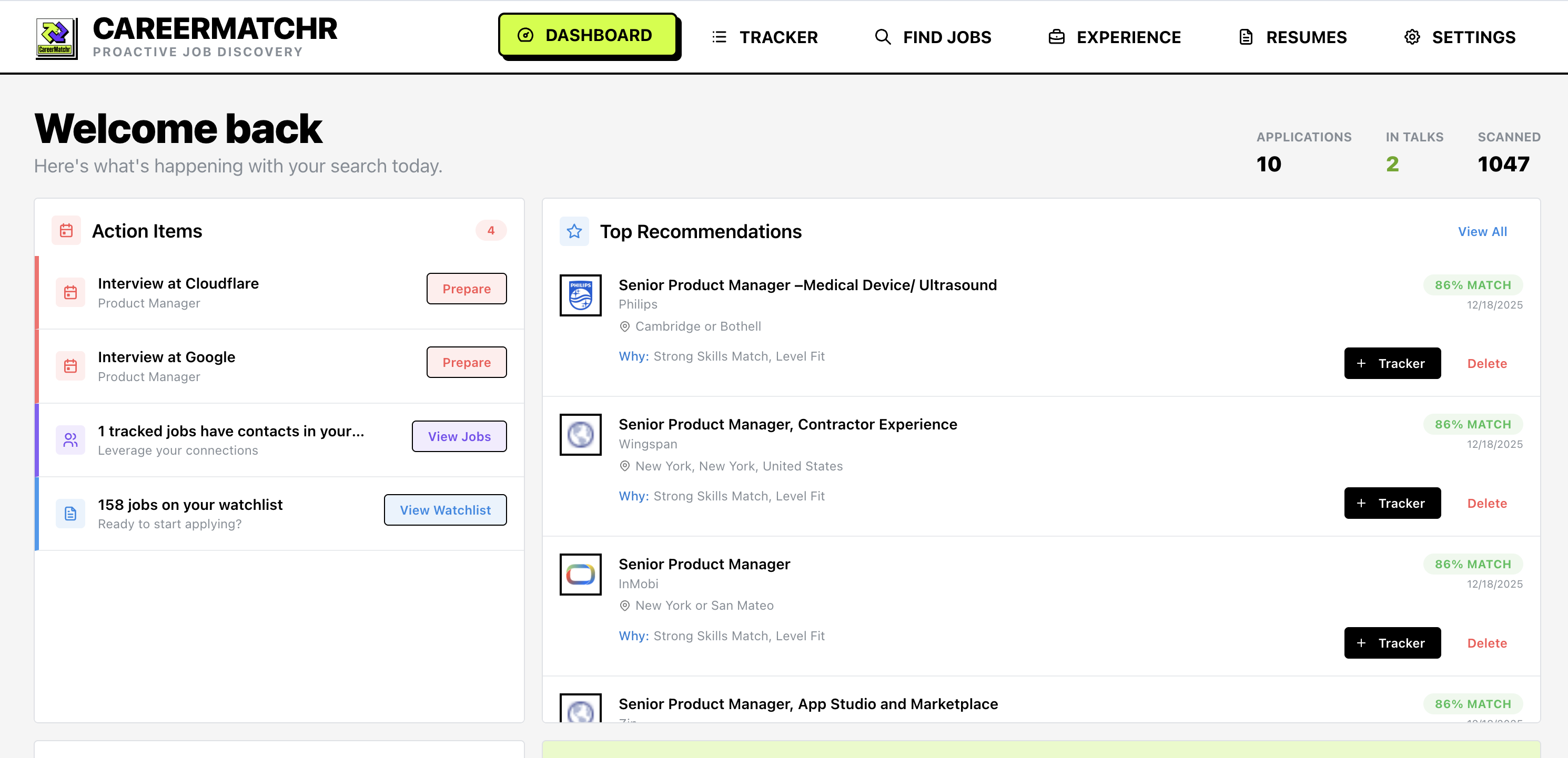
Modern job boards have been slow to adopt AI on the user facing side. Tools like LinkedIn, Indeed, and trackers like SkillSyncer all function primarily as databases and presentation layer. They rely on users to proactively find roles, review job description, and assess fit. While some platforms are now offering AI solutions for search and “matching”, they often come at a hefty premium.
My goal was to invert this process. Instead of a user checking alerts, pushing data into a tracker, and tailoring resume content. I wanted a system that pulled together the users experience context, and relevant opportunities from the web, and presented only the “high-signal” options for review and submission.
Part I: Automating Discovery
The initial prototype was a standard Kanban board with a scraper/data import pipeline. While it streamlined data entry, it didn’t solve the core inefficiency: discovery. I was still spending hours manually sourcing data. So I looked for solutions.
![]()
Most job board APIs are often intended for enterprise customers doing job market research. This makes these APIs expensive and sometimes even restricted to enterprise accounts. Then I found out that LLMs could serve as a cost-effective alternative for scraping and structuring raw HTML from company job posting sites.
By setting up a scheduled ingestion pipeline, I had built a system that scans ~800 sources daily. It filters distinct job postings against a “Target Role” definition and pushes valid matches to the dashboard, removing the need for manual searching.
Part II: Data Quality Issues
Limitations of Naive RAG Early tests using a standard “resume + structured job details” prompt yielded poor results. The LLMs frequently hallucinated skills or misclassified experience.
The results were dangerously mediocre. The LLM would misclassify experience and hallucinate skills. It lacked the semantic understanding and details needed because a resume is just lossy compression of the users work experience.
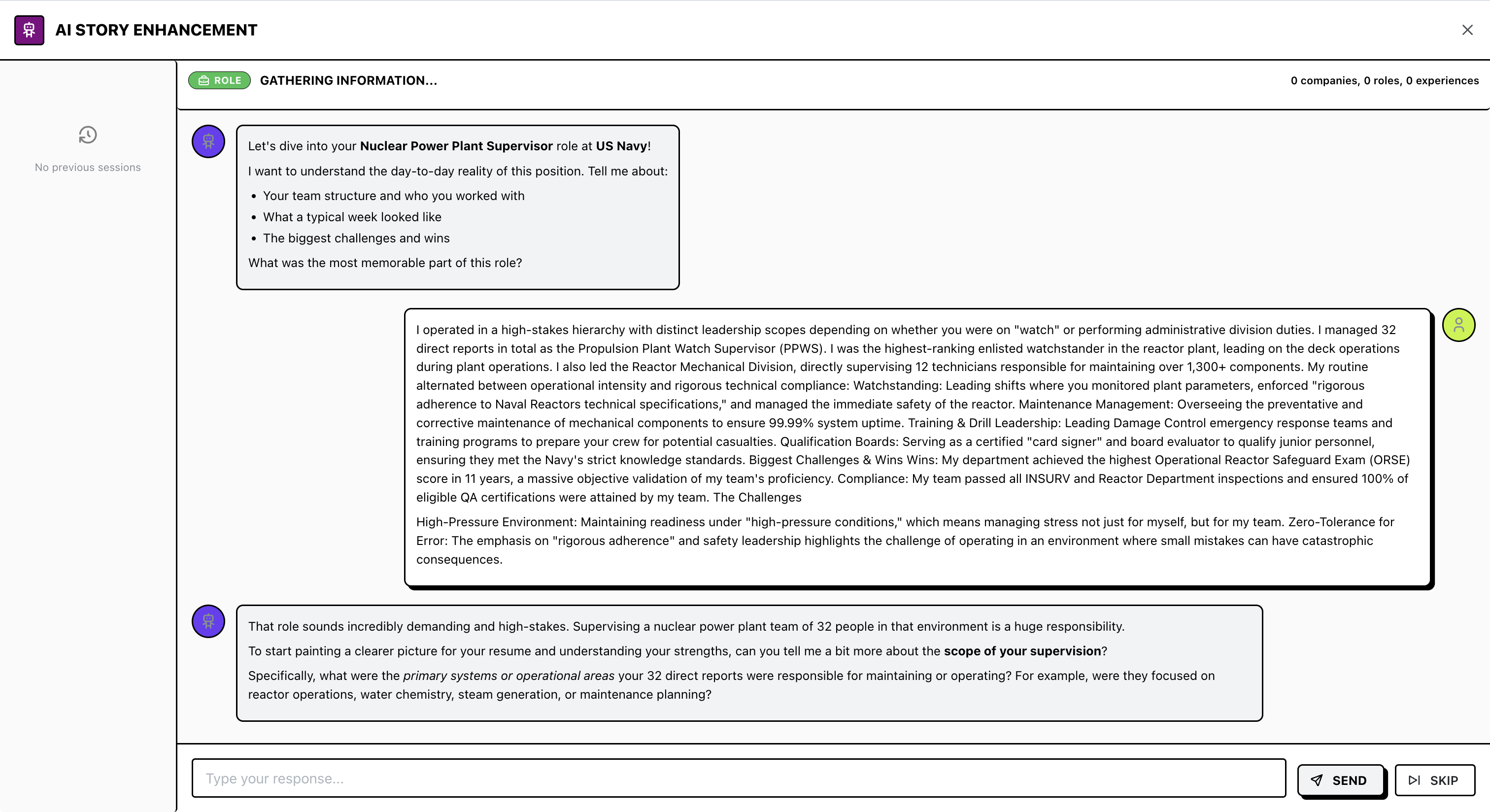
To fix this, I implemented a Context Extraction Workflow. Rather than relying on a one-page resume, the system uses a chat interface to “interview” the user. It prompts for specific details (team size, tech stack, outcomes) until it has enough information to populate a structured JSON schema.
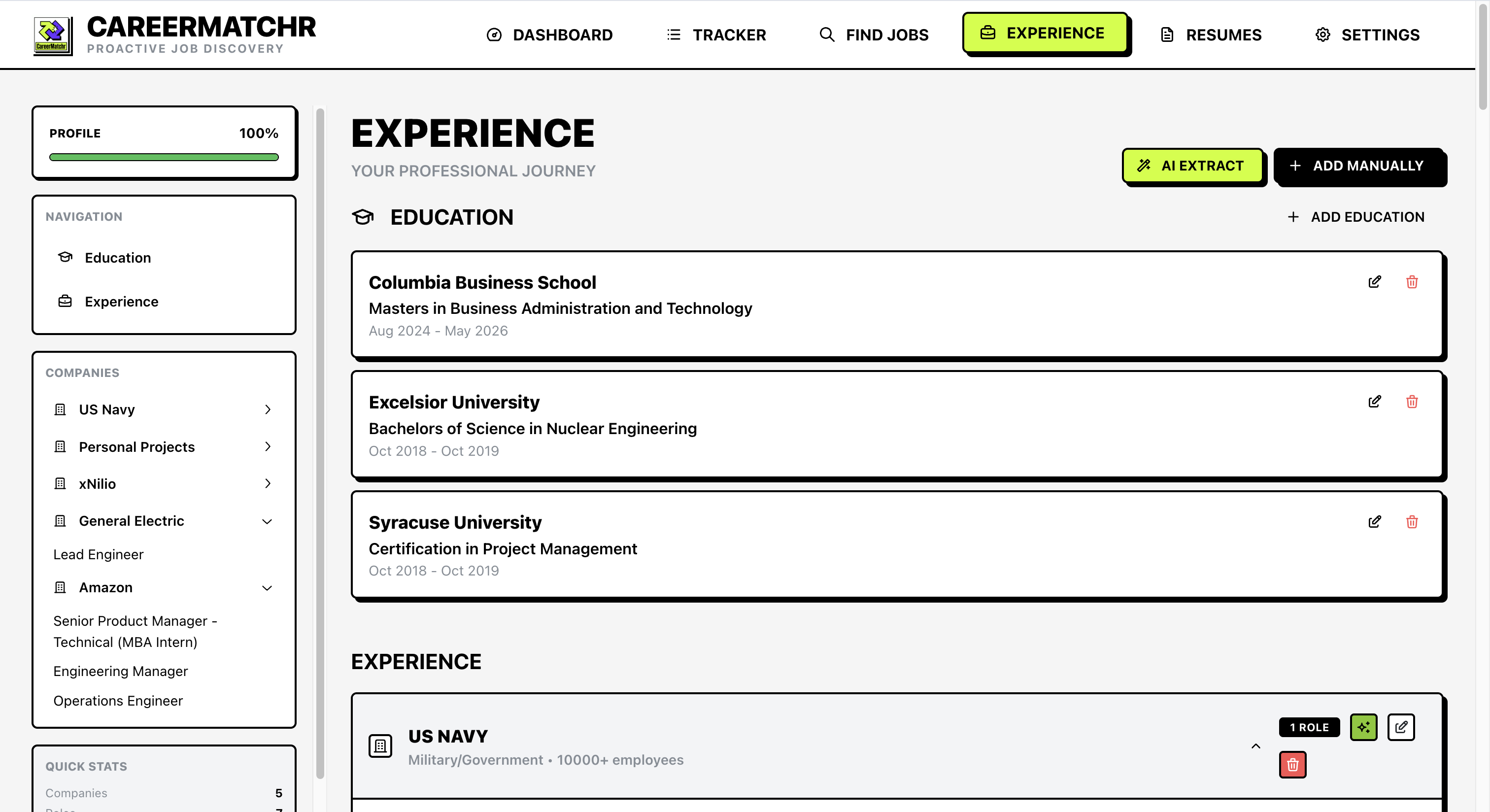
This creates a comprehensive Experience Database. Now when the system evaluates a match, it references this deep context rather than inferring experience based on a few keywords.
Part III: Architecture & Trade-offs
The backend was designed to handle high-volume text processing without incurring massive API costs.
Moving Inference to the Edge As the volume of job scans increased, paid embedding APIs became a cost prohibitive bottleneck.
- Solution: Migrated to a local instance of BGE-M3 for vector embeddings.
- Result: Elimination of per-token costs and improved retrieval density for technical terminology compared to generalist cloud models.
The Stack
- Queueing:
BullMQ+Redishandles the asynchronous ingestion and scoring pipeline, ensuring the UI remains non-blocking during large batch scans. - Backend:
Fastify(Node.js) for lower overhead compared to Express. - Data Layer:
PostgreSQL+Prismato manage the relational complexity between Jobs, Skills, and Embedding Vectors.