AI Chinese Language Learning App
Full-stack AI-powered language learning application with custom ML models for translation and real-time tone correction.
DuShuo: Chinese learning from the content I actually consume
What I’ve built (so far)
Chrome extension: pinyin overlay + hover definitions + one-click vocab saves + video subtitle layer (pinyin/English/Chinese overlays for platforms like Netflix/Bilibili/Disney+).
Dictionary foundation: merged + normalized ~123k entries; added context/examples/metadata via an ETL pipeline using API calls to LLMs. Built multiple Evals for quality and cost optimization.
Generative quizzes: established question generation prompt, and schema for 21 different question types (multiple choice, open response, cloze fill, grammar, etc.) with grading and feedback.
Implemented Speech to Text module to provide a real-time karaoke-like tone feedback experience. After testing a mix of different methods I ultimately settled on MFCC and normalize audio input for its simplicity and accuracy.
My role: end-to-end product + engineering (research, UX, backend, frontend, model routing, evaluation + cost).
DuShuo: Extension-first
I built DuShuo because I felt the content I was using to learn Chinese was not the content I actually enjoyed consuming. When I did find a show or article that I liked, I’d get frustrated by the amount of time it took to look up the meaning of a word I didn’t know. I often needed to look at multiple sources to truely understand the meaning and nuances of a word, which would cause me to break flow bouncing between tabs and applications (dictionary → notes → flashcards → back to content). The friction was small, but it happened often enough that I decided I needed a tool to help me learn Chinese.
In my search for a tool to help me learn Chinese, I found that most of the tools available were either too simple, or too expensive for the limited utility. So I came up with the idea for Dushuo - 读说. It started as a Chrome extension that turns any chinese character on a webpage into an engaging learning tool. It allowed users to hover a word for meaning, display pinyin, and save vocabulary in one click. In follow up itterations it allowed users to attach the same layer to streaming subtitles. Through a mix of subtitle extraction, and ASR powered STT. This required a bit of magic to get right, but it was a fun challenge to buffer the audio stream, and align it with the subtitle stream. Thanks to open source models like SenseVoice Small, I was able to run this on my own hardware, and build in model optimizations to make it run fast and reliable.
Part II: Building the Data Foundation
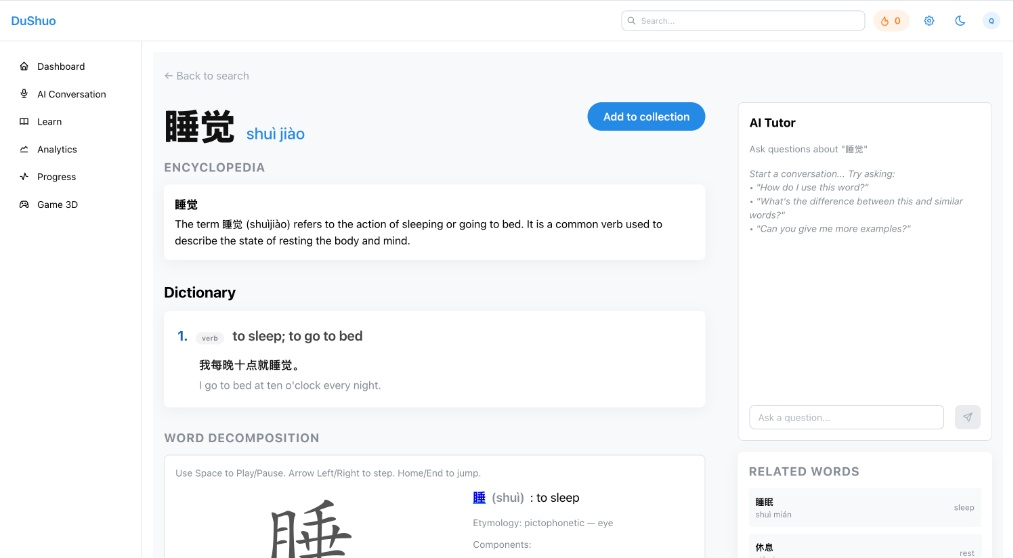
Building the dictionary: LLM Pipelines & Data Enhancement
As I started to collect vocabulary terms, and organize them into collections, I realized that I needed a proper dictionary to tie into the extension. Sources like CC-CEDICT, Moedict, Baidu’s Baike, and Unihan provided a solid foundation, but they each lacked the pedagogical metadata needed for a true learning platform, often lacking a complete set of features that describe modern usage, nuance (“formal”, “internet slang”, “polite but stiff”), senses, parts of speech, patterns, and related terms.
So I built an ETL pipeline that merges multiple sources and then enriches entries using LLMs into a unified schema that is useful.
Final Schema Priorities
The resulting dictionary structure was optimized for:
- Decomposition — Radical and component breakdown for character learning
- Context — Encyclopedic descriptions from Baike enrichment
- Parts of Speech — Grammatical categorization for sentence construction
- Social Nuance — Register, formality, and usage context
- Semantic Relations — Related words and synonyms for vocabulary expansion
- Vector Embeddings — BGE-M3 embeddings for hybrid search (dense + sparse)
Part III: Generative quizzes: my main goal was reliability, not creativity
I wanted infinite practice items without shipping a brittle hand-authored question bank. But letting a LLM free-write questions would lead to unparseable outputs that aren’t compatible with a non-chat UI. So I sought out to create a system where quizzes are generated via tool calling with strict schemas. The model can be creative inside constraints, but the output always matches what the frontend expects. In my testing, question generation stayed under ~1–2 seconds and I was able to produce a diverse set of questions that were unique yet relevant to the user’s learning experience.
The point here isn’t that we should use LLMs to do everything, it’s that Useful AI systems are personal and efficient, and successful implementations need a contract (explicit context + schema + validation).
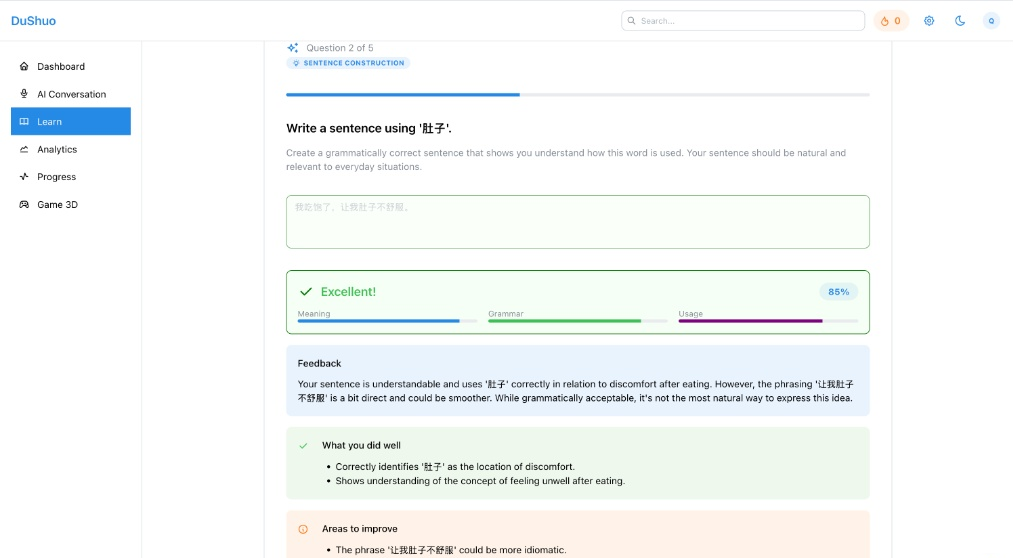
I chose to use LLMs here because standard SRS (Spaced Repetition Systems) like Anki or Quizlet fail to capture the nuance required for true language mastery. A simple “Did you know this?” binary doesn’t distinguish between:
- Recognizing a word in multiple choice
- Producing the word in a sentence
- Using proper tone in speech
- Selecting the socially appropriate synonym
By leveraging LLM Tool Calling, the system forces AI to generate quiz questions that adhere to strict JSON schemas while maintaining the creativity to produce infinite variations:
{
"question_type": "fill_in_blank",
"target_word": "考虑",
"context_sentence": "我们需要____一下这个计划的可行性。",
"options": ["考虑", "考试", "考察", "考验"],
"difficulty": "intermediate",
"bloom_level": "application"
}Question Types Generated
Vocabulary
Multiple Choice
Word to Meaning (“What does 你好 mean?”),
Meaning to Word (“Which word means hello?”),
Choose correct among visually similar (己 vs 已 vs 巳),
Identify within selected collection,
Identify pinyin tone vs noisy alternatives,
Audio recognition → match to characters
Open Response
Define in English, Use in a sentence, Audio recognition → type characters, Type the definition, Cloze Fill (select words from bank)
Grammar
Multiple Choice
Match grammar usage (CN→EN),
Match grammar usage (EN→CN),
Identify incorrect usage,
Distinguish similar structures (best/any applies)
Open Response
Explain (English),
Use in a sentence
Reading
Multiple Choice
Reading comprehension (difficulty per form)
Open Response
Reading comprehension (Open),
Translate the passage,
Typing practice (test for speed and accuracy)
Integrated Grading & Feedback
The LLM doesn’t just generate questions — it also provides tailored feedback by analyzing:
- The user’s answer against expected patterns
- Socially uncommon word usage
- The user’s active vocabulary collection for context-aware hints
The Mathematics of Memory: BKT + Elo Learner Model
The Depth vs. Frequency Framework: Optimizing the Learning Curve
Standard SRS systems have a critical flaw: they treat all successful recalls equally. But cognitively, correctly selecting “狗” from a multiple-choice list is fundamentally different from correctly using “狗” in an original sentence.
Bayesian Knowledge Tracing (BKT) Implementation
The learner model uses BKT to estimate mastery probability based on performance history:
# BKT Parameters
BKT_P_INIT = 0.3 # Initial knowledge probability
BKT_P_LEARN = 0.3 # Learning rate
BKT_P_GUESS = 0.25 # Guess probability
BKT_P_SLIP = 0.1 # Slip probability
def compute_bkt_mastery(correct_count, total_count):
if correct_rate > p_guess:
evidence = (correct_rate - p_guess) / (1.0 - p_guess - p_slip)
p_known = p_init + (1 - p_init) * evidence * p_learn * total_count
return max(0.0, min(1.0, p_known))Elo Rating for Item Difficulty
Combined with Elo ratings to match learner ability with item difficulty:
Expected Score = 1 / (1 + 10^((opponent_rating - current_rating) / 400))
New Rating = current_rating + K * (actual_score - expected_score)Target Selection Categories
| Category | Mastery Range | Ratio | Purpose |
|---|---|---|---|
| Review | BKT < 0.4 | 30% | Reinforce struggling skills |
| Practice | BKT 0.4-0.7 | 50% | Consolidate learning |
| Challenge | BKT > 0.7 | 20% | Push into i+1 territory |
6-Dimensional Skill Embedding System
Each vocabulary item tracks mastery across six cognitive dimensions:
| Dimension | Type | Cognitive Focus |
|---|---|---|
| emb_pinyin_recall | Recognition | Can identify correct pinyin |
| emb_meaning_recall | Recognition | Can identify correct meaning |
| emb_pronunciation_recall | Recognition | Can identify correct pronunciation |
| emb_usage_reproduction | Production | Can use word in context |
| emb_meaning_reproduction | Production | Can produce translation |
| emb_pronunciation_reproduction | Production | Can speak correctly |
This multi-dimensional approach allows the system to identify specific weaknesses rather than treating vocabulary as monolithic units.
Decision History: Why BKT + Elo Over Alternatives?
| Alternative Considered | Why Rejected |
|---|---|
| Simple SM2 | No probabilistic mastery estimation; binary pass/fail |
| Half-Life Regression (HLR) | Requires more historical data; cold-start problem |
| Deep Knowledge Tracing (DKT) | Neural network overhead; interpretability issues |
| Pure Elo | Designed for competition, not learning progression |
Why BKT + Elo Hybrid?
- BKT for mastery — Probabilistic model works well with sparse data
- Elo for difficulty matching — Matches learner to appropriate challenge level
- Interpretable — Can explain “you have 65% mastery of this word”
- Computationally light — No GPU required; runs on every request